


Let’s say you’ve been running experiments for a while. Your experimentation program generally feels stable but how do you know if you’re progressing or just caught in a test and learn cycle?
More experiments isn’t necessarily an indication that your programs maturity is increasing. The difference between a program that genuinely moves the needle and one that just keeps the lights on comes down to four things:
- how you generate and prioritise ideas
- how you run and learn from tests
- how you turn results into strategy
- …and whether the culture around you actually supports any of it.
These aren’t boxes you tick once. They’re dimensions you develop over time, at different rates, with different bottlenecks at each stage.
This is what the experimentation maturity model is really about. Not a badge. A diagnostic.
Why Maturity Models Matter (And Where Most Get Them Wrong)
There are a few versions of experimentation maturity models floating around. Most of them describe what a mature program looks like without telling you how to get there. They hand you a picture of the destination and call it a map.
The other problem: most models treat maturity as linear. You start at Stage 1, you work through to Stage 4, done. But real programs don’t move that way. A company can have genuinely sophisticated statistical rigour and completely broken insight management. Another can have brilliant strategic alignment but a backlog built entirely on guesswork. You can be Stage 3 in process and Stage 1 in culture simultaneously. The model only helps you if it shows you where you actually are across each dimension, not just where you sit overall.
So here’s how I look at it. Four stages, four dimensions. The stages describe the overall arc of how programs develop. The dimensions tell you where the real work lives.
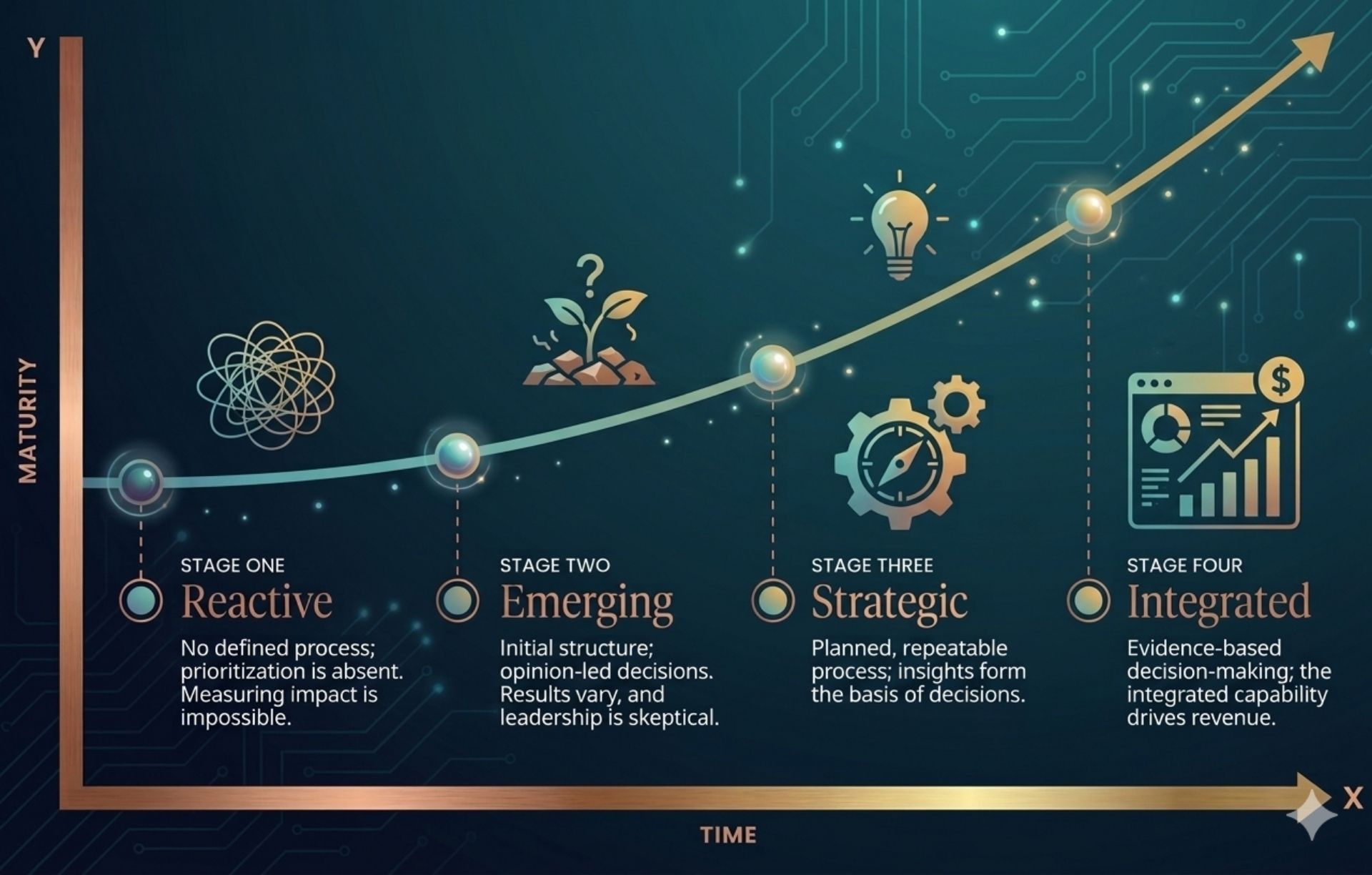
Stage One: Reactive
Nearly every program starts here. The honest ones admit it.
At Stage 1, testing happens when someone has an idea and the bandwidth to act on it. There’s no formal process. Prioritisation is whoever shouts loudest or whoever holds budget. Tests run when the dev team has a gap. Results get announced in a Slack message and then quietly forgotten unless they win, in which case they get shipped and nobody looks back.
The defining characteristic of Stage 1 isn’t a lack of ambition. It’s a lack of infrastructure. There’s usually one person driving tests, sometimes two. They’re doing everything. Writing briefs, chasing implementation, reading results, communicating findings. The program exists in their head, not in any system.
Losses are treated as failures. This is the tell. At Stage 1, a losing test is a bad outcome. Teams feel embarrassed by them. They question whether the test was set up correctly, whether the hypothesis was wrong, whether CRO is even working. What they don’t do is ask what the loss revealed about user behaviour, because the mental model isn’t there yet.
If you’re at Stage 1, the priority isn’t velocity. It’s foundations. One documented process that everyone follows. A basic hypothesis structure. A consistent way of capturing and storing results. That’s it. Not a tool. Not a framework. A habit.
The most common mistake at this stage is trying to scale before the basics work. You can’t run 20 tests a month if you can’t run 5 tests a month cleanly. Fix the process for five, then scale.
Stage Two: Emerging
Something shifts at Stage 2. The program gets formalised. There’s a roadmap. There’s a backlog. Some process and a regular meeting where tests get reviewed. More people are involved and there’s a rough agreement on how things should work.
This is where many programs plateau. And they plateau here specifically because Stage 2 feels like a mature program from the inside.
The process looks professional. The output is consistent. Tests are documented, results are shared and there’s a growing library of experiments. But underneath, the program is still largely reactive. Ideas still come from opinions, from competitor activity, from whatever the latest product meeting surfaced. Prioritisation uses a scoring framework, often PIE or ICE, but in practice it still reflects who championed an idea rather than what the evidence actually supports.
PIE scores effort, importance, and confidence. ICE scores impact, confidence, and ease. Both are useful, but both are also easy to game. If the person filling in the scores is the same person proposing the ideas, the scores will reflect their optimism. At Stage 2, this is almost always what’s happening.
The insight layer is also underdeveloped. Tests run, tests conclude, results go into a spreadsheet or a slide deck, and the learnings sit there. Nobody is synthesising them. Nobody is asking what three consecutive tests on the same page are telling you about how users think. The learnings exist but they don’t compound.
What to focus on here:
- Separate idea generation from idea prioritisation
- Get different people doing each
- Start building a simple taxonomy for your learnings so that results from six months ago can actually inform what you test next month.
That taxonomy doesn’t need to be sophisticated. Category, page, user behaviour, finding. Four columns is enough to start.
Stage Three: Strategic
Stage 3 programs look different in a specific way. The experiments connect to something larger than themselves.
At Stage 2, you run tests. At Stage 3, you run programmes of tests. There’s a research phase that informs a hypothesis. The hypothesis connects to a known gap in the customer journey. The test result, win or loss, feeds back into a model of how users behave on that journey. The next test builds on that model.
This is what it actually means to learn from experimentation. Not reading individual results. Building cumulative understanding.
A retail client I worked with was running tests on their product detail pages at Stage 2. Lots of them. Layout changes, image sizes, button colours. Some won, most didn’t. After eighteen months, they couldn’t tell you anything meaningful about why their conversion rate was 2.1% and not 3.5%. They had test results. They had no understanding.
The shift to Stage 3 started when they stopped asking “what should we test?” and started asking “what don’t we understand about why people don’t buy?” Three qualitative sessions later, they found that users didn’t trust the returns process. They tested messaging around returns policy in five different configurations. Four of the five lifted conversion. The fifth revealed an edge case around international delivery that led to a product change that was never on anyone’s roadmap.
That’s Stage 3. The experiment is the research method, not the output.
When experimentation is connected to strategy, it starts interfering with how decisions get made.
Culture starts becoming visible as a bottleneck here. When experimentation is connected to strategy, it starts interfering with how decisions get made. Product managers who used to ship features based on intuition are now being asked to wait for results. Stakeholders who wanted a launch date are being told there’s a test to run first. This is where buy-in becomes a genuine challenge, not just a nice-to-have.
Stage 3 programs invest in that buy-in deliberately. They track and share program metrics, not just test metrics. Velocity, win rate by category, impact on OKRs, cost per insight. They make the program legible to the people who fund it.
Stage Four: Integrated
Stage 4 is rare. I’ve seen elements of it at companies like Booking.com, Netflix, and in pockets of large retailers who’ve been at this for more than a decade. It’s not a destination most programs need to target immediately. But it’s worth understanding what it looks like, because it tells you what you’re building toward.
At Stage 4, experimentation is a decision-making infrastructure, not a team or a process. It’s not that there’s a great CRO team. It’s that the organisation doesn’t make meaningful product or commercial decisions without experimentation as part of the process. The question isn’t “should we test this?” The question is “how do we test this?”
Technically, Stage 4 programs are running multiple experiment types simultaneously. A/B tests for UI changes. Holdout tests for feature releases. Multivariate tests for content. Geo-based tests for pricing. The statistical models are more sophisticated and the teams understand them. There’s usually a data science function directly integrated with the experimentation practice.
Insight management at Stage 4 is systematic. There’s a knowledge base. There are tags. There are search functions. New researchers can pull up everything the program has learned about checkout anxiety in under ten minutes, because the institutional knowledge lives in a system and not in one person’s memory.
Critically, Stage 4 programs have solved the culture problem. Losses are genuinely celebrated, not as a performance of psychological safety, but because the organisation has internalised that the point of testing is to find out the truth. A losing test that saves you from shipping a bad feature is worth more than a winning test that confirms something you already believed. Stage 4 teams know this and act like it.
The bottleneck at Stage 4 is almost always one of two things: tooling that can’t keep pace with volume and complexity, or the politics of scaling a culture across business units that weren’t built with experimentation in mind.
What Separates Each Stage Across the Four Dimensions
Across all four stages, the differences show up consistently in the same four places.
Process is about how tests get from idea to conclusion. At Stage 1 it’s informal and person-dependent. At Stage 2 it’s documented but not enforced. At Stage 3 it’s enforced and integrated with research. At Stage 4 it’s automated, monitored, and continuously improved.
Strategy is about whether the tests connect to the business. At Stage 1 there’s no connection. At Stage 2 there’s a nominal connection through OKRs or quarterly goals but it’s loose. At Stage 3 the experimentation roadmap is derived from strategy. At Stage 4 strategy is informed by experimentation as much as it informs it.
Insight management is about what happens to what you learn. At Stage 1, nothing happens. At Stage 2 results are stored. At Stage 3 results are synthesised. At Stage 4 results are searchable, tagged, and actively used to build models of user behaviour.
Culture is about how the organisation treats the program. At Stage 1 it’s tolerated or ignored. At Stage 2 it’s accepted as a process. At Stage 3 it’s respected but still challenged when it creates friction. At Stage 4 it’s a core capability that the business would fight to protect.
How to Actually Move Forward
The programs that stall do so because they focus on the wrong dimension. A Stage 2 program that tries to solve culture without fixing insight management will never get traction, because stakeholders will keep seeing disconnected results with no cumulative narrative. A Stage 3 program that neglects process will generate brilliant insights and then fail to act on them at speed.
The first thing to do is get honest about where you actually are, not where you’d like to be. This means assessing all four dimensions separately. A program that scores Stage 3 on process and Stage 1 on culture is a Stage 1 program with a good process. Culture is the ceiling.
Second: pick one dimension and one specific gap within it. Not “improve our insight management.” Specifically: build a tagging taxonomy for test results so that learnings from Q1 can be queried by Q3. Specific enough that you know whether you’ve done it.
Third: measure the program itself. Not just test results. How long does it take from idea submission to test live? What percentage of tests are reaching statistical significance? What’s the win rate by hypothesis category? These program metrics tell you whether your process is actually working, separate from whether any individual test won.
The reason this matters is that most program leaders only look at test results. If tests are winning, the program is healthy. If tests are losing, something is wrong. That’s exactly backwards from how mature programs think. A high win rate with low test velocity and no strategic connection is a failing program. A moderate win rate with clear learnings, high velocity, and direct connection to strategic priorities is a healthy one.
If you want to know exactly where your program sits right now across all four dimensions, take our Experimentation Maturity Quiz to get your personalised score. It takes about five minutes, covers process, strategy, insight management, and culture separately and gives you a clear picture of where your biggest gap is and what to do about it first.


